
From Idea to Launching AI: A 5-Week Journey for Founders and Solo Builders (Part 1)
The Foundation — Validating Your AI Idea & Building Your MVP


We all know that AI spending is skyrocketing. The phrases “make it smarter,” “automate things,” or “users expect AI now” have led the global AI market to hit $391 billion in 2024 and business spending on generative AI to reach $13.8 billion (600% increase from the previous year).
Yet, 74% of companies aren’t achieving meaningful value from their AI initiatives. I am also one of the victims here who learned this lesson the hard way. I spent six months and $40,000 building a sophisticated model to predict customer behavior that worked technically but delivered zero paying customers.
The truth is simple: building an AI system isn’t about flashing algorithms or shiny demos. It’s about solving a real pain point and delivering a system that customers will actually use. That’s why I created this comprehensive three-part series, which will guide you through the entire AI startup journey, including idea validation, MVP design, deployment, scaling, and more.
In this first part of the series, we will cover:
How to validate your AI idea using real customer pain points rather than hype.
When and when not to use AI.
Connect AI capabilities to business outcomes.
How to build your Minimum Viable AI System.
Stick around to move from “Al-first” thinking to a validated problem brief and a lean MVP that sets the stage for long-term success.
Validating Your AI Idea: Building With Purpose, Not Hype
You have an idea. It’s exciting. Your mind is already racing with possibilities about the models you could use and the features you could build. Stop right there.
The most dangerous phase of any AI project is that initial burst of excitement. When most founders set out to build an AI product, they start with the wrong question: “How can we add AI?” Instead, the real question should be: “What painful, costly problem can AI actually solve for my users?”
The AI gold rush has created a dangerous trap. Teams are chasing buzzwords instead of business outcomes. This is why insufficient problem definition is the #1 reason AI projects fail, surpassing even technical challenges.
You need a filter to separate genuinely good ideas from ones that sound cool. That filter is the PAIN Framework.
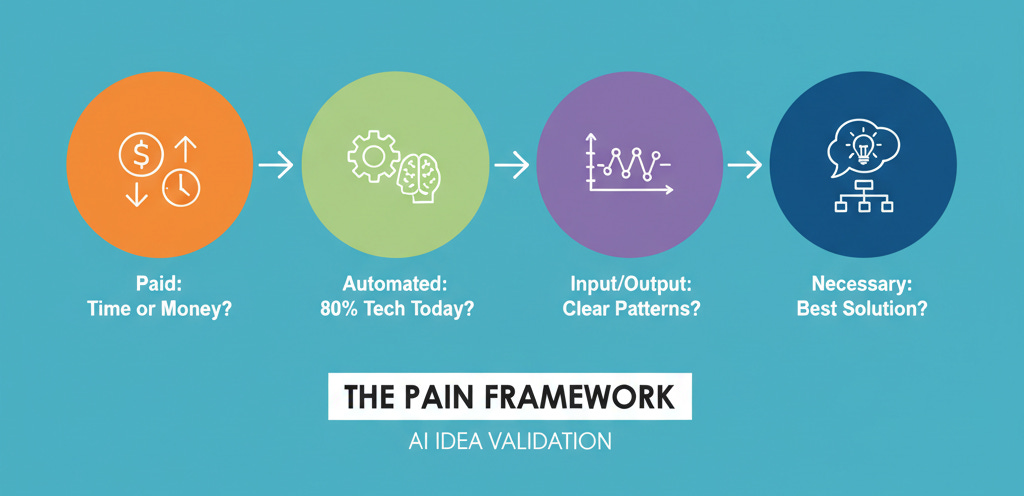
The PAIN Framework for Idea Validation
The PAIN framework is a simple four-question litmus test every AI idea should pass:
P – Paid: Is the user already paying (time or money) to solve this? If not, your solution won’t gain traction.
A – Automatable: Can 80% of the problem be solved with off-the-shelf tech today? If so, you probably don’t need AI.
I – Input/Output Patterns: Do real data show precise and repeatable patterns that AI can learn?
N – Necessary: Is AI the best solution compared to better UI, improved docs, or simpler workflows?
Rule of thumb: If you get a single “NO” when you run through these questions, take a step back. You might have an interesting concept, but you don’t yet have a viable AI business.
I will provide a real-world example of how I utilize the PAIN test when clients approach me for AI projects.
A founder was building a recruiting platform. The original plan was to utilize AI to predict job success based on resumes. It sounded exciting, but the PAIN test revealed the flaws:
Painful enough? Resume screening was a hassle, but not painful enough to pay more for predictions.
Automatable? Success prediction was too complex and biased for current AI.
Identifiable patterns? Job success patterns were too messy. The culture and team fit can’t be modeled efficiently.
Necessary? No. The real issue was disorganized resumes, not a lack of predictions.
The founder then shifted focus to an AI-driven resume parsing and organization tool. Less flashy, but it addressed the real pain point. Today, the platform supports over 500 agencies with a 95% customer retention rate.
Takeaway: Solve the real pain, not the flashy problem. Spend time with potential users and look for the elements that frustrate them. You will identify issues they are trying to solve many times or tasks they feel overwhelmed with. These then become the pain points where AI might deliver value.
When (and When not) to Use AI
Let’s assume that you have found a genuine problem that passes the PAIN test. The next critical decision is to choose the right tool for the job. This is where many founders stumble, as they opt for a complex AI solution when a simpler one would be more effective.
I learned this lesson painfully when I spent three weeks building a machine learning model for sentiment analysis that achieved an accuracy of 87%. However, I eventually discovered that a simple keyword-based system could reach 83% accuracy in just five minutes. I had wasted weeks on a marginal gain that users couldn’t even perceive.
This experience taught me the 80/20 Rule of AI Implementation. You can often solve 80% of the problem with 20% of the complexity.
Check out this simple decision tree for choosing the right approach:
Start with rules-based systems when:
Clear and consistent logic governs the problem
You need complete transparency and explainability
Every millisecond of latency matters
You have little to no training data
Choose traditional programming when:
Direct coding is possible due to a deterministic solution
Strict performance requirements
Audit trails and explainable decisions to fulfill regulatory compliance
Lack of AI/ML expertise or resources
Choose pre-trained APIs when:
You are dealing with standard tasks, such as text analysis or image recognition
Speed to market is crucial
You want professional-grade capabilities without the development overhead
Consider custom AI only when:
Patterns are too complex for manual rules
You have abundant and high-quality training data
Some uncertainty in outputs is acceptable
The problem justifies the development and maintenance costs
Suppose we apply the above decision tree to practical examples. In that case, we can see that AI is a good fit for fraud detection across millions of transactions and personalization with extensive behavioral datasets. On the other hand, ticket routing by department and form validation are considered a bad fit for AI.
Remember: If a rules-based system gets you 90% of the way there with minimal complexity, ship it. You can always add intelligence later once you have real users and data.
Connect Your AI Capabilities to Business Outcomes
I have seen many times that a team celebrates a new model achieving high accuracy, while the business team sees no movement in revenue or user growth. This occurs when we optimize for technical metrics rather than business outcomes.
The most successful AI founders I know are ruthless about one thing. They can draw a straight line from their AI’s output to a key business metric. They don’t build features because they are cool. They build them to move the needle.
Bridging the AI-Business Gap
The alignment between AI and business outcomes doesn’t happen by accident. I use the three-step play below to help founders create this alignment:
Identify Your 2-3 Key Business Metrics. Forget vanity metrics. What numbers directly impact your survival? Is it customer lifetime value? Monthly churn? Transaction volume? Pick the vital few.
Map AI to Metric Movement. Next, get specific with each key metric. Instead of “AI will increase revenue,” frame it as: “We improve [Gross Margin] by [our pricing model] that [suggests optimal prices], reducing [manual decision time] by [75%].” This creates a clear and testable hypothesis.
Set Success Criteria Before You Build. Decide upfront: What accuracy is “good enough”? What improvement in the business metric would make this project worthwhile? This prevents you from tuning a model endlessly for diminishing returns.
The Dashboard That Matters
Build a simple weekly dashboard that tracks three layers:
AI Performance – (Accuracy, Latency)
Product Adoption – (Are people using the feature?)
Business Impact – (Is it actually improving our key metrics?)
I saw the above model transform into a pricing tool. A founder had built an AI price optimization model for e-commerce sites with great accuracy, but no customers. We pivoted his focus from “prediction accuracy” to his customers’ key metrics, i.e., gross margin and time spent on pricing. He simplified the AI to deliver precise and actionable recommendations that directly moved those needles. The result? His product now generates over $1 million a year.
Bonus Tip: I have found the “time-to-value metric” to be crucial in evaluating AI products. It measures how quickly users start seeing real value. The shorter this timeframe, the stronger the adoption and retention.
Building Your Minimum Viable AI System (MV-AI-S)
Now comes the moment to build something real. Before that, you need another critical mindset shift. You are not creating a Minimum Viable AI. You are building a Minimum Viable AI System. What’s the difference?
An AI model takes inputs and produces outputs. An AI System delivers actual value to users. This distinction is everything. Simply put, an AI system is a model + rules + UX + feedback loops. The end goal is a product that users trust and get value from immediately.
I saw this play out dramatically with one founder who built a legal document analyzer. Her AI could identify contract clauses with 96% accuracy, which was better than most junior lawyers. Yet she had zero customers. Why? Because law firms needed integration with their existing software, bulk processing, and custom workflows she hadn’t built.
The technology worked, but the system around it was incomplete. This leads us to set the mindset that:
Your MV-AI-S isn’t about your model’s accuracy. It’s about solving the user’s complete problem. Users hire your system to make their lives easier, not to admire the sophistication of your algorithm.
Considering this, we improved her product by shifting the focus from model performance to user workflow. We transformed it from a sophisticated document analyzer to a simple clause extraction tool that could integrate with lawyers’ existing workflows.
The result? Within three months, she had 127 paying law firms. The accuracy had dropped by 7%, but it was irrelevant to lawyers who were now saving two hours per contract review. The lesson was clear: users don’t buy AI accuracy. They buy solutions to their workflow problems.
Key Design Principles for MV-AI-S
There are four key design principles to consider for building a successful minimum viable AI system:
Hybrid Intelligence: Use rules for predictable cases, AI for messy edge-cases, and humans for exceptions.
Progressive Disclosure: Ship simple and high-value automation first. Reveal advanced AI features only after users trust the product.
Confidence-Based UX: Clearly communicate AI uncertainty to users, so they know when to trust outputs. Utilize visual confidence indicators, provide alternatives for low-confidence cases, and enable quick human verification to maintain trust and control.
Day 1 Value: Ensure AI features deliver immediate utility, even without user data, to overcome the cold start problem. Provide defaults, rules for common cases, fast onboarding, and clear value within minutes.
Together, these reduce user friction and create a natural upgrade path from rules → API → ML.
Model Selection: Stop Building Ferraris
When it comes to AI, everyone wants to use “advanced” AI. They want to talk about their cutting-edge deep learning models. However, this mindset is a runway killer for MVP. In fact, it is one of the most expensive mistakes to choose a complex model when a simple one would work.
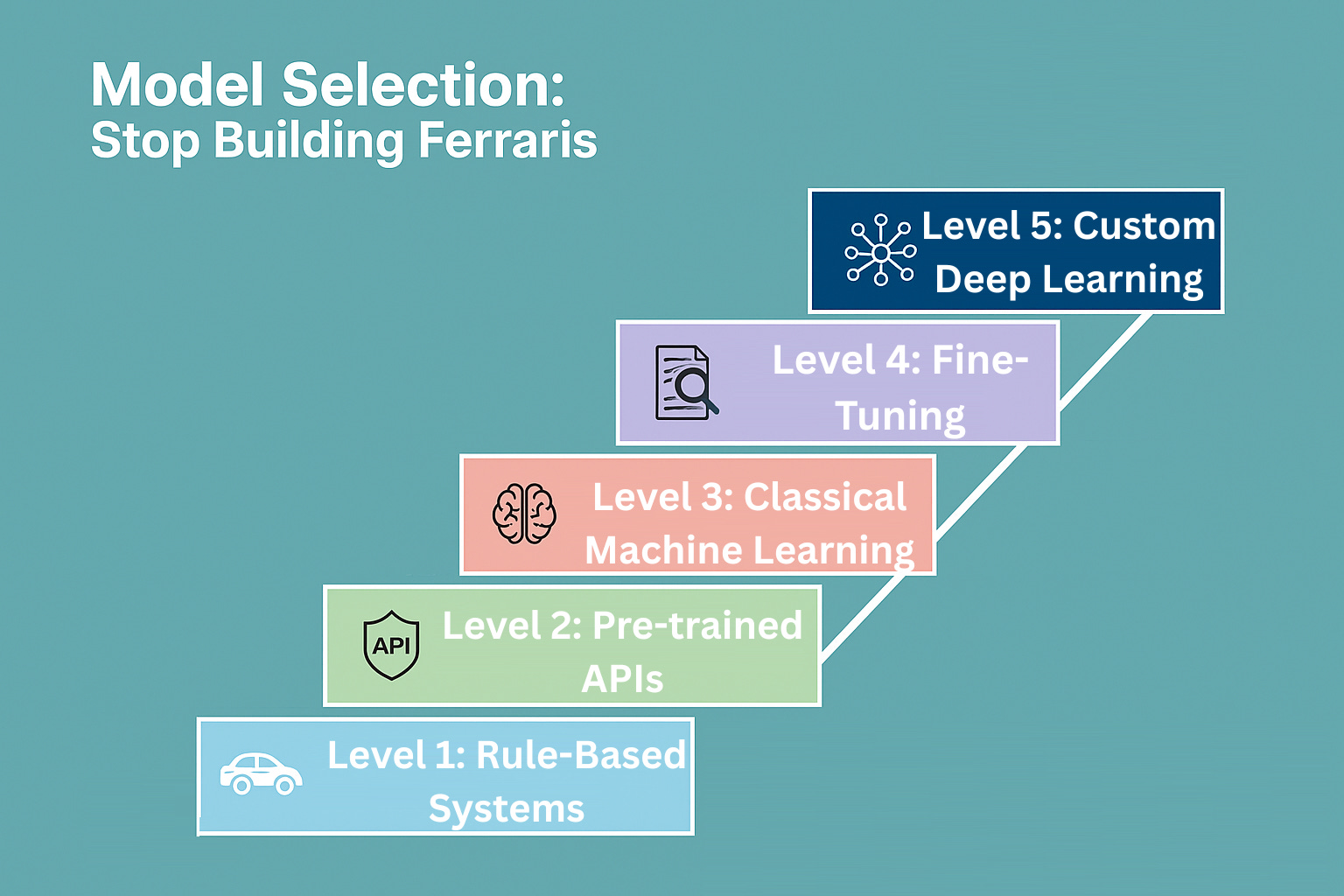
Resist the hype and follow this proven selection ladder when choosing the model:
Level 1: Rule-Based Systems. Start with rule-based systems if you have clear logic like “flag emails from the boss as ‘high priority’” because they are fast and foolproof.
Level 2: Pre-trained APIs. For standard tasks such as text summarization or image recognition, consider using OpenAI or Google’s APIs. Get sophisticated results in days, not months.
Level 3: Classical Machine Learning. For structured data, like predicting customer churn from usage history, algorithms (Random Forests) are fast and need less data.
Level 4: Fine-Tuning. Use only if you have thousands of examples and a domain-specific need, such as a medical document classifier.
Level 5: Custom Deep Learning. Use only for unique problems with massive datasets and a dedicated research team.
Checklist for Model Selection
I have created a list of questions that I ask myself whenever selecting a model in my projects:
Can rules solve 80% of the problem? If yes, start there.
Is there a pre-trained API available? If yes, use it.
Do I have high-quality data for training custom ML models? 1,000+ examples per class for classical ML, or 10,000+ for deep learning.
Do I need to understand model decisions? If yes, prioritize interpretable models over black-box approaches.
What are my latency requirements? Real-time needs simpler models.
What’s my infrastructure budget? Complex models get expensive fast.
Does my team have the expertise? Avoid selecting a model that your team cannot implement.
What’s my timeline for market validation? Simple models enable you to gather users’ feedback faster.
These questions will help you figure out whether an advanced approach is necessary or if simple solutions can work for you.
I'm sharing an example of a founder who built a real estate pricing AI system. He wanted to use deep learning with hundreds of property features, but the data was messy and expensive to prepare. Therefore, he switched to a simple linear regression model, incorporating key features such as location and size. The result was an 85% accurate and transparent model that shipped in weeks and won client trust.
The lesson? Sophistication doesn’t always win. Simplicity and speed often matter more.
Data Strategy From Day One
You can have the most advanced algorithm in the world, but you will get bad results if you feed it with bad data. Most startups approach data backwards. They build a model first, then search for data to train it. This creates a foundation of technical debt that can sink your product.
The core challenge is the AI Data Bootstrapping Problem. You need data to build a valuable AI, but you need a valuable AI to attract users who give you data.
So, how do you break in? Use these practical cold-start strategies:
● Public Datasets: Kickstart development with open datasets from sources like Kaggle, Google Dataset Search, or UCI ML Repository. They won’t set you apart in the long term, but they are perfect for validating concepts and building your first models.
Synthetic Data: Generate artificial examples that reflect real patterns, beneficial for images (augmentation, style transfer), text (paraphrasing, back-translation), or simulations (fraud, logistics). This allows you to obtain volume without waiting for real-world data.
Human-in-the-Loop: Build your product so every user action becomes training fuel. Over time, these interactions create a self-reinforcing data flywheel that steadily improves your AI.
Partner Data: Collaborate with organizations that possess rich datasets but lack AI capabilities. You can offer AI services in exchange for access.
The Non-Negotiable Rules of Data Quality
Data quality is crucial for the reliability of your AI system. However, the question is how to ensure data quality? So, I have set up five rules for this purpose:
Completeness: Ensure critical fields aren’t missing. Gaps in data lead to skewed models. Aim for clear thresholds and automatically flag incomplete records.
Accuracy: Wrong labels teach wrong lessons. Use validation rules, outlier detection, and human review to maintain the trustworthiness of data.
Consistency: Data should adhere to the same format, schema, and naming conventions throughout. Inconsistencies create confusion and integration failures.
Timeliness: Old data quickly loses relevance in fast-moving domains. Set freshness requirements and automate checks for stale inputs.
Representativeness: Your data must mirror real-world diversity. Watch for demographic or behavioral biases that could make your AI unfair or unreliable.

Build with Ethics and Trust
Your data strategy is also a trust strategy. Practice data minimization by collecting only what is necessary, obtaining informed consent, and conducting regular audits to identify and mitigate bias. This is both ethical and a competitive advantage that builds long-term user trust and mitigates massive regulatory risks.
The goal is a progressive strategy where users get immediate value and willingly contribute to a system that gets smarter for everyone.
Prototyping with Pre-Trained Models
Why spend months building a custom model from scratch when you can utilize the power of giants? Services like OpenAI, Hugging Face, AWS, and Google Cloud offer sophisticated AI capabilities through simple API calls. They have turned what was once a PhD-level project into an afternoon’s work.
The key is to use them strategically. Don’t build a custom sentiment analysis model when GPT-4 can do it with a clever prompt. Don’t develop a computer vision system from scratch when Google’s Vision API already excels at object detection.
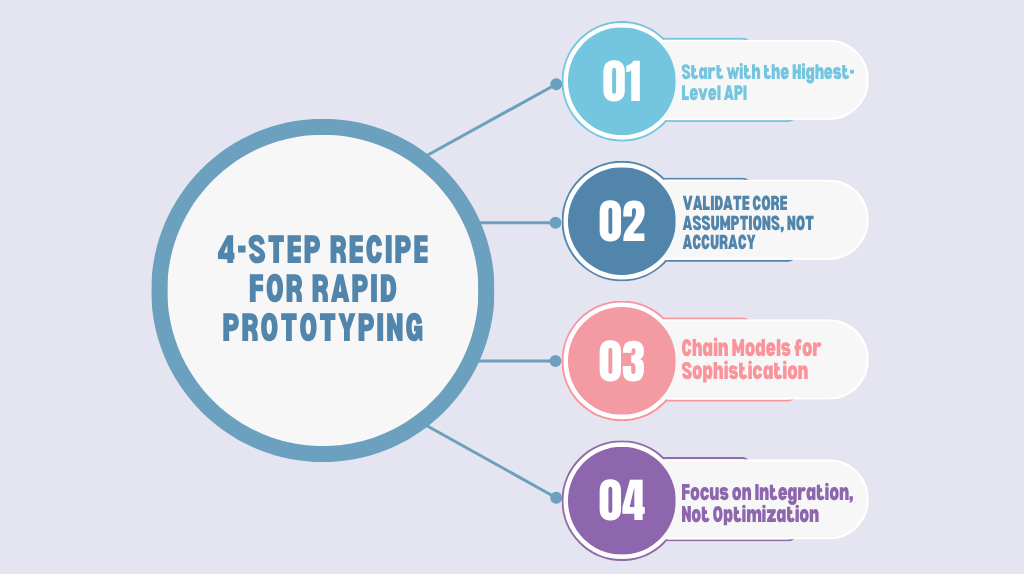
4-Step Recipe for Rapid Prototyping
Start with the Highest-Level API: Use the most abstracted service available. Need to understand text? Start with ChatGPT’s API before considering more complex options.
Validate Core Assumptions, Not Accuracy: Build the simplest version of your feature and present it to users immediately. The goal is to test if the AI provides value, not if it’s perfect.
Chain Models for Sophistication: Combine APIs to Create Powerful Workflows. For example, use a vision API to read a document, then a language API to summarize its key points.
Focus on Integration, Not Optimization: Spend your time making the AI feel smooth in your users’ workflow. A well-integrated and 85%-accurate tool is far better than an accurate one that’s clunky to use.
Let me share an example to illustrate the importance of rapid prototyping more effectively. A founder needed to route customer support tickets. His plan for a custom classifier would have taken months. Instead, we built a prototype in two days using GPT-3.5 to categorize tickets and a simple rules engine for routing. It was only 78% accurate, but it immediately proved the concept and revealed crucial user requirements we hadn’t considered.
Intelligent Cost Control with Pre-Trained Models
Pre-trained models may seem inexpensive, but costs can quickly escalate. Therefore, it is essential to follow the practice of intelligent cost control:
Cache results to avoid reprocessing identical requests.
Use cheaper models, such as GPT-3.5, for initial filtering and reserve GPT-4 for the most complex tasks.
Preprocess inputs to remove unnecessary text and reduce token usage.
Perform batch processing of similar requests into a single API call.
Track API usage and optimize high-cost workflows to improve efficiency.
These strategies can let you validate your AI idea in days, not months, and invest in custom models only when you have proven user demand.
The Validation Paradox: AI Can “Work” and Still Fail
Beware the demo that works perfectly. The biggest AI mistake is scaling a technically sound model that users find useless. I built an image recognition tool with 94% accuracy, only to find users saw it as broken. Why? They expected 100% reliability from the software.
This is the validation paradox: technical perfection ≠ user value.
Users don’t care about your F1 score. They care about completing their task. An AI that’s 90% accurate but causes frustration has failed. An AI that’s 80% accurate but saves time has won.
The 3-Phase Framework to Validate
Validation requires observing real people using your AI for real-world tasks. Here is the 3-phase framework to validate:
Phase 1: Qualitative Deep Dives (5-10 Users)
Watch real people use your AI. Listen for sighs of frustration, watch where they get confused, and notice when they stop trusting the system. Key questions to answer:
Can users complete their actual tasks?
How do they recover from AI mistakes?
Does the AI fit naturally into their workflow?
Phase 2: Controlled Pilots (25-50 Users)
Expand your testing and start measuring what actually matters:
Task success rate (not just accuracy)
Time-to-value (how long until users get meaningful benefit)
Error recovery rate (can users work around mistakes?)
Adoption patterns (which features do people actually use?)
Phase 3: Iterative Refinement (100-200 users)
Use your insights to improve both the AI and the user experience systematically:
Add confidence indicators so users know when to trust the AI.
Provide clear explanations for AI decisions.
Create easy feedback mechanisms to correct mistakes.
Metrics That Actually Predict Success
Stop obsessing over technical metrics. Track what really matters:
User Success:
Can people complete their tasks?
How quickly do they see value?
Do they come back and use it regularly?
Business Impact:
Does it save time or reduce costs?
Does it improve user satisfaction?
Does it drive revenue or retention?
In short, the goal is not just to prove that your AI is accurate. It’s to prove that users will adopt it into their daily workflow. Validate with real users doing real work, and remember that a technically imperfect solution that people actually use is always better than a perfect solution they abandon.
Conclusion
If there’s one thing to remember from all of this, it’s this: “Boring and valuable beats brilliant and brittle.” Your goal in this foundational phase isn’t to build a masterpiece of engineering. It’s to find out if you are creating the right thing for the right people.
We’ve covered the essential blueprint:
Find the Real Pain: Use the PAIN Framework to ensure you are solving a problem people actually care about.
Choose the Right Tool: Apply the “AI or Not?” decision tree to avoid over-engineering and start with the simplest solution.
Build the System, Not Just the AI: Focus your MV-AI-S on the complete user workflow, not just the model’s accuracy.
This week, your mission is not to train a model or write complex code. It’s to have three conversations with potential users. Take your idea and run it through the PAIN Framework. That single and simple action will put you ahead of the vast majority of projects that fail from a lack of validation.
Now that you have validated your idea and built a prototype, Part 2 will engineer your prototype for reality. You will learn the scalable architecture to handle traffic, the essential MLOps to maintain your AI, deployment, and serving at scale, and much more. We will transform your validated idea into a solid system.